
Twelve Labs is a developer‑first video intelligence platform that provides multimodal foundation models and APIs for semantic search, analysis, and recommendation across large video libraries. It excels at understanding what’s happening inside videos across visuals, audio, speech, and on‑screen text and exposing that understanding via simple APIs, making it a strong choice for video‑heavy products in media, sports, edtech, and enterprise knowledge. However, it is fully managed and video‑centric, so teams looking for self‑hosted or broad, all‑content‑types search might find it narrower than generalized RAG or self‑hosted multimodal stacks.
Twelve Labs describes itself as a “video intelligence platform & API” that lets organizations “find anything, discover deep insights, analyze, remix and automate workflows with AI that can see, hear, and reason across your entire video content.” The company showcases collaborations with ecosystem players like NVIDIA and emphasizes its focus on enterprise‑grade video understanding, highlighting endorsements that reference “world‑class” video understanding and NVIDIA‑accelerated computing.
The company builds on a strong research foundation in computer vision and video understanding, with work presented at top conferences (ECCV, CVPR) and wins in LSMDC challenges, showing it goes beyond simply applying generic LLMs.
Its vision is to usher in a new era of video understanding by connecting video libraries to foundation models like Marengo and Pegasus, delivered through APIs positioning itself as the core infrastructure for video-native AI applications.
At a product level, Twelve Labs is best understood as a video understanding platform with three core capabilities: Search, Analyze, and Embed, all built on top of video‑native multimodal models.
The product overview page pitches this as “for everything you want to do with video,” from semantic search and content recommenders to novel generative applications. The platform ingests raw video content, applies video‑native models that “see, hear, and reason,” and exposes the resulting understanding via APIs that can power both internal workflows and user‑facing features.
| Capability | What it does | Typical use cases |
| Search | Find specific moments within videos by describing the scene in natural language; search across speech, on‑screen text, audio, and visuals. | Semantic video search, Q&A over archives, contextual clip retrieval. |
| Analyze | Generate text from videos: summaries, chapters, highlights, social posts, and more. | Automatic highlight reels, TOCs, meeting notes, social copy. |
| Embed | Produce multimodal embeddings that are “fast, precise, context‑aware” for search, recommendations, and clustering across large libraries. | Recommendation engines, similarity search, personalization, content intelligence. |
The product experience is anchored around a playground and a catalog of sample apps and tutorials so developers can see these capabilities in action before wiring them into production systems.
While Twelve Labs does not open‑source its models, it gives a conceptual view of a video‑native multimodal architecture on its homepage and product pages. The core idea is that raw video libraries are passed through models such as Marengo and Pegasus to produce video embeddings that understand time, space, and multiple modalities simultaneously.
The platform emphasizes “multimodal AI that understands time and space,” implying that its models consider:
● Visual frames (objects, people, scenes, actions).
● Audio tracks (non‑speech sounds, tone, environment).
● Spoken language via automatic speech recognition (ASR).
● On‑screen text via OCR, enabling search across both dialogue and textual overlays.
Instead of treating video as a bag of frames or just a transcript, Twelve Labs fuses these signals into embeddings that reflect what is happening, where, and when in a clip. That temporal and multimodal awareness is what enables queries like “show me the moment where the host picks up the red product box and smiles” rather than just “find the word ‘box’ in the transcript.”
The homepage’s conceptual pipeline is: RAW VIDEO LIBRARY → MODELS (Marengo, Pegasus) → VIDEO EMBEDDINGS → SEARCH API, ANALYZE API, EMBED API. This is essentially “foundation model as a service” for video:
● Search API uses embeddings to execute semantic text‑to‑video or image‑to‑video searches.
● Analyze API uses video understanding to generate summaries, chapters, highlights, and other text outputs conditioned on the video content.
● Embed API exposes raw embeddings so teams can build their own retrieval, recommendation, or clustering logic.
The presence of multiple model families suggests that the platform will continue to refine specialized models (e.g., tuned for short‑form content, sports, or ads) while maintaining a general backbone.
Although the detailed API reference isn’t reproduced on the marketing pages, Twelve Labs strongly emphasizes a developer‑friendly flow through its product overview, playground, and tutorials.
The product page prompts developers to “try” Search, Analyze, and Embed with sample apps. Examples include:
● Olympics Video Clips Classification Application – categorizes different Olympic sports using video clips.
● Shade Finder App – uses image‑to‑video search to find specific color shades in videos, such as a particular lipstick tone.
● Generate social media posts for your videos – an app that takes videos and generates platform‑specific social posts via Analyze.
● Video Highlight Generator – automatically creates chapters and highlights for long‑form content using video analysis.
● Contextual and Personalized Ads – analyzes source footage, summarizes it, and recommends ads based on context and emotional tone.
● Recommendations using Multimodal Embeddings – explores similar content powered by Twelve Labs embeddings.
Each tutorial is presented as a way to “take the reins with quick‑start tutorials,” often including both concept and code. For a developer audience, this lowers activation energy: you can see end‑to‑end examples before building custom pipelines.
A typical integration with Twelve Labs involves first ingesting and indexing video content into the platform, then waiting for it to be processed into embeddings and metadata. Once processed, developers can use the Search, Analyze, or Embed APIs to retrieve relevant segments, generate text outputs, or access embeddings for their own search or indexing systems. These results are then integrated into applications, such as highlight reels, semantic search features, recommendation systems, or analytics dashboards.
This model‑as‑an‑API approach is familiar to teams that already consume NLP or vision models from cloud providers, but with a deeper focus on long‑form video.
Twelve Labs markets itself as “powering the future of video understanding across industries,” and the combination of sample apps and copy gives a clear view of where it shines.
The homepage references generating “content tailored to each fan while maintaining the brand identity of each team preserved in team‑specific generative models,” hinting at sports and media personalization use cases. The Video Highlight Generator tutorial directly supports workflows like automated highlight reels and chapters for long‑form sports or entertainment content.
In practice, this might look like:
● Automatically generating personalized highlight reels for each fan based on their favorite players or moments.
● Enabling deep archive search across decades of footage using natural language queries.
The “Contextual and Personalized Ads” sample app suggests a strong focus on ad tech: the platform can analyze source footage, summarize it, and recommend ads based on context and emotional tone, enabling more relevant and brand‑safe ad placements. Because the models look at visuals, audio, and text, they can, in principle, distinguish between similar phrases used in different contexts (e.g., violent vs instructional scenes).
Several tutorials target creators and marketers:
● Generate social media posts for your videos to automate cross‑platform promotion workflows.
● Analyze social media posts for your videos to streamline performance analysis and content iteration.
Combined with highlight generation and summarization, this makes Twelve Labs a strong backend for SaaS tools that help creators repurpose long‑form video into short clips, captions, and posts.
The Interview Analyzer tutorial demonstrates how video analysis can evaluate job interview performance and extract insights from video-based conversations. The same approach can be extended to other use cases, such as training libraries where lectures are indexed and searchable, or internal knowledge bases of recorded meetings, enabling users to find specific moments like product demos or discussions on particular policies.
The Shade Finder tutorial shows that even niche, visually specific use cases (like finding a particular color shade across videos) are feasible via image‑to‑video search. This opens up applications in fashion, beauty, manufacturing QA, and design.
Twelve Labs promotes a “Play for free. Pay as you go.” pricing philosophy, with three broad segments on both the homepage and product pages.
All three tiers share the same basic functional shape but differ in limits and deployment environment:
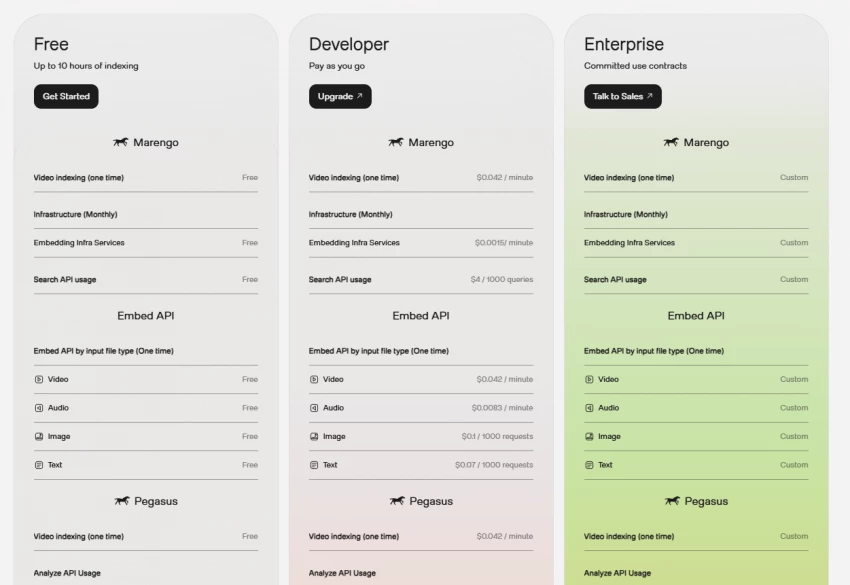
This structure maps neatly onto startup → scale‑up → enterprise adoption patterns, where early users experiment on shared infrastructure, and large customers graduate to dedicated environments with higher guarantees and deeper customization.
Although the exact unit pricing (per minute indexed, per query, etc.) is not detailed in the marketing copy, the combination of:
● Free testing with limited indexing, and
● Clear paths to unlimited indexing and dedicated environments
suggests a classic usage‑based SaaS pattern suitable for both early‑stage builders and large media enterprises. For organizations with thousands of hours of video, the main ROI drivers will be reduced manual tagging, better content discovery, and new personalization or automation features unlocked by semantic understanding.
From the public material, several strengths stand out:
1. Video‑native focus : The platform is built around the idea of “multimodal AI that understands time and space,” with dedicated video models (Marengo, Pegasus) rather than generic image or text models retrofitted to video.
2. Rich multimodal understanding : Search and analysis operate across visuals, speech, audio, and on‑screen text, providing a more holistic understanding of video content than transcript‑only approaches.
3. Developer‑friendly entry points : Playground, sample apps, and quick‑start tutorials for tasks like highlights, ads, recommendations, and interviews offer concrete starting points for builders.
4. Scalable, managed infrastructure : The tiered plan structure with shared vs dedicated environments and unlimited indexing options indicates readiness for enterprise‑scale workloads.
There are also some trade‑offs to be aware of:
1. Cloud‑only, proprietary stack : The site emphasizes a fully managed environment; teams that require on‑prem or self‑hosted models for compliance or cost reasons may need to look elsewhere or push for custom arrangements.
2. Video‑centric scope : Twelve Labs is razor‑focused on video. If your primary need is a single search system across video, documents, images, and other unstructured data, you may need to combine it with additional tooling.
3. Opaque internal metrics : While the company claims state‑of‑the‑art video understanding, the marketing pages do not expose detailed quantitative benchmarks, making independent testing crucial for mission‑critical deployments.
Twelve Labs is well-suited for media platforms, broadcasters, and streaming services that need deep semantic search and automated highlight generation across large video libraries. It also benefits sports leagues and teams looking to deliver personalized content and insights to fans at scale.
It is equally valuable for creator tools and social video platforms, where automated clipping, summaries, and cross-platform content generation are essential for efficiency and growth.
It also supports edtech and training platforms that require detailed indexing of long-form content, as well as enterprises with large internal video libraries such as meetings, trainings, and demos seeking better search and analytics capabilities.
Organizations outside of these video‑heavy domains can still benefit, but the platform’s strengths are clearest when video is a core asset, not a side channel.
Twelve Labs sits at the intersection of foundation model providers, with a focus on video rather than just text or images, and search and recommendation infrastructure, where embeddings and semantic retrieval power user-facing features.
It also extends into workflow and automation tools, enabling AI-driven video production, analysis, and content lifecycle management.
Its homepage prominently lists “TRUSTED BY” and highlights collaborations (for example, NVIDIA and other large partners) as well as a commitment to “ongoing research” and “harnessing AI potential safely, and for good.” This signals that the company is targeting long‑term infrastructure partnerships rather than short‑lived point solutions.
Given its current positioning and product lineup, Twelve Labs could deepen vertical specialization in areas like sports, advertising, and education by offering tailored models and templates. It may also pursue tighter integration with cloud providers and data platforms, allowing seamless indexing and querying within existing analytics ecosystems.
At the same time, the platform could expand into generation capabilities, combining video understanding with editing or creation workflows, while introducing clearer benchmarks and evaluation tools to help enterprises measure performance and monitor quality over time.
For now, Twelve Labs is clearly focused on being the best‑in‑class option for understanding and retrieving information from video; how it expands beyond that will likely depend on demand from its largest customers.
Twelve Labs delivers a compelling, video‑native AI platform for teams that treat video as a primary data asset rather than a marketing afterthought. Its multimodal models, search/analyze/embed APIs, and rich library of sample apps make it particularly attractive for media, sports, edtech, and enterprise platforms that need semantic search, highlights, summaries, and recommendations on top of large video archives.
The trade‑offs are that it is a proprietary, managed service with a strong but narrow focus on video; teams demanding self‑hosted solutions or a single system spanning all content modalities may pair it with other tools. For organizations willing to adopt a cloud‑hosted video AI backbone, however, Twelve Labs stands out as one of the most specialized and ambitious offerings in the space.
1. Can Twelve Labs be self‑hosted on‑premises?
The platform is designed and offered as a managed cloud service. Organizations with strict on‑prem or self‑hosting requirements usually need to evaluate whether its deployment model aligns with their compliance and infrastructure policies.
2. Does Twelve Labs support image‑to‑video search?
Yes. Image‑to‑video search is a key use case, allowing a reference image such as a product, outfit, or scene to be used as a query to locate visually similar moments across indexed videos.
3. Is Twelve Labs suitable for real‑time or live video scenarios?
Twelve Labs is primarily positioned around processing recorded video libraries. For strict real‑time or low‑latency live scenarios, teams generally need to evaluate whether current ingestion and processing latency meets their requirements.
4. Does Twelve Labs support multilingual content?
Support for non‑English content depends on the underlying speech recognition and language capabilities configured. Teams working with multilingual video typically need to test performance on their target languages and review official language‑support information.
5. Is Twelve Labs only for large enterprises, or can startups use it too?
The tiered pricing model includes lower‑volume plans suitable for testing and early‑stage products, as well as higher‑volume, dedicated‑environment plans aimed at large enterprises, making it viable across company sizes.

In recent months, CrossMarket.ai has quietly gained attention across social medi...
Ina Gupta11 hours ago

HINAI Web is an enterprise‑grade, web‑based Hospital Information / Health Inform...
Noura Belkacem1 week ago

FaceCheck ID sits at a strange intersection of online safety, facial recognition...
Funke Ogunleye1 week ago

A student opens their laptop in exam season, looks at the stack of PDFs, s...
Grace Howard1 week ago

ThinkWave is trying to solve a very specific problem: schools drowning in spread...
Noura Belkacem2 weeks ago

Voomixi.com is the kind of site that makes big promises without saying much out...
Noura Belkacem2 weeks ago
Discussion